
기본 데이터 형식
- CPU 연산 장치
- ALU(Arithmetic Logic Unit) : 정수만 처리하는 장치
- FPU(Floating Point Unit) : 부동 소수점만 처리하는 장치
- 따라서 CPU에게 데이터 종류에 따라 명령을 내려야 함.
- CPU는 데이터 타입 판단 능력 없음.
- 컴파일러가 대리 업무
- 숫자 데이터 형식
- 정수형 : 9가지
- 왤케 많음?
- 닭 잡는데 소 잡는 칼 쓸 수 없다고, 실제 사용되는 리터럴의 크기에 비해 과한 크기의 메모리 선언은 낭비이기 때문.

- 추가로 char도 정수형
- 1 바이트(byte) == 8비트(bit)
- 바이트는 메모리의 주소나 CPU 처리하는 데이터의 단위.
예제
- 2진수, 10진수, 16진수 리터럴
- 2진수 리터럴 : 0b 접두사
- byte a = 0b1111_0000;
- 언더바(_)는 자릿수 구분자는 2진수, 10진수, 16진수
- 16진수 리터럴 : 0x 접두사
- byte b = 0XF0;
- 2진수 리터럴 : 0b 접두사
- 부호

- 부호 있는 정수 : sbyte, short, int, long
- 부호 없는 정수 : byte, ushort, uint, ulong
- 8비트 : 2*2*2*2*2*2*2*2 = 256가지
- sbyte는 -128~127, byte는 0~255까지로 두 자료형의 표현 범위가 다른 이유?

- Q. 아래의 sbyte형의 비트는 어떤 값일까?

정답
A. -1
- 부호와 절댓값 방식 : 아래와 같이 0에 부호가 붙는 문제를 해결하기 위해 2의 보수법으로 음수 표현
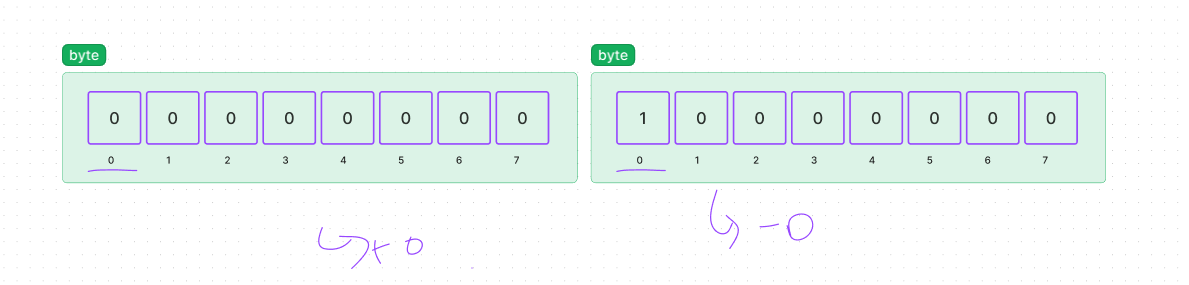
- 2의 보수법
- 특정 양수 값의 비트를 계산.
- 해당 값의 각 비트를 변환
- 변환된 값에 +1
- Overflow
- 이러한 자료형의 범위를 벗어나면 어떻게 될까?

- 표현 가능한 범위는 여전히 8bit이므로 0으로 돌아간다.
- 이렇게 자료형의 최댓값을 넘어서 값에 변형이 생기거나 오류가 발생하는 것을 Overflow라 한다.
- 마찬가지로 최저값보다 작은 데이터를 저장한다면 Underflow가 발생한다.
- 이러한 자료형의 범위를 벗어나면 어떻게 될까?
- char : 정수 계열임
- 정수형 : 9가지
- 부동 소수점 형식 (뜰 부 + 움직일 동 : 소수점이 떠다니며 움직인다)
- 소수점을 이동시키면 고정했을 때보다 넓은 범위의 값을 표현 가능.
- 이미지 예시
- 정수형의 대체제로 사용 불가한 이유
- 소수점 표현으로 인한 표현 범위의 상대적 크기
- 연산 과정이 정수 계열보다 복잡하고 느림.

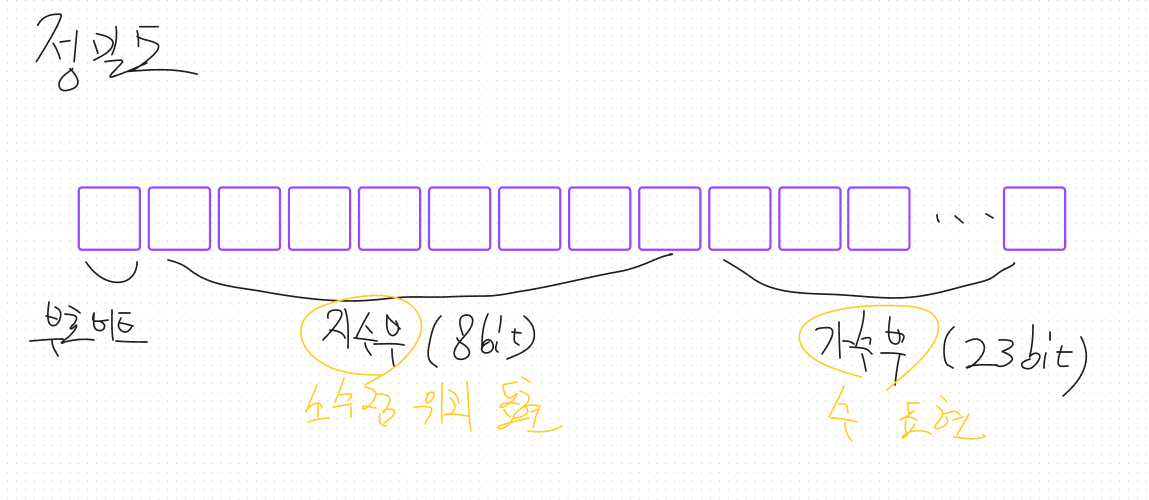
- 단일 정밀도 : 넓은 범위의 수에 비해 표현 가능한 수는 7자리.
- 따라서 나머지 수는 대략적으로 표현해야함 == 한정된 정밀도를 갖고있음.
- 복수 정밀도 : float에 비해 두 배의 메모리를 사용.
- 이것들이 부동 소수점 형식의 한계.
- 더불어 double이 float에 비해 메모리 사용량은 두배를 차지하지만, 데이터 손실이 그만큼 적기 때문에 double사용을 추천.
- double보다도 데이터 손실이 적길 원하면 demical을 사용하고, 그보다 적길 원한다면 직접 자료형을 작성해야한다.
- demical타입
- 29자리 데이터 표현 가능, 16바이트(128비트)
- 소수 표현 방식 조사 필요
- 문자형과 문자열 형식
- 문자열 형식 : string(”어떤 물건이 연속해서 가지런하게 놓여 있는 줄”)
- 변수에 담는 텍스트의 양에 따라 크기가 달라짐.
- 여러 줄을 담는 문자열
- 줄바꿈 문자
string multiStr = "동해물과 백두산이\n마르고 닳도록";
- 큰따옴표 세 개
string multiStr = """ 동해물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라 만세 """;
- 줄바꿈 문자
- 문자열 형식 : string(”어떤 물건이 연속해서 가지런하게 놓여 있는 줄”)
- 논리 형식(Boolean Type)
- 참 / 거짓
- 크기 : 1바이트(8비트)
- bool형식은 1비트 만으로 표현 가능하나, 컴퓨터가 다루는 기본 데이터 단위가 바이트기 때문.
- Object 형식
- 어떤 데이터도 다룰 수 있는 데이터 형식
- (사용자 정의 자료형 포함) 모든 데이터 타입은 자동으로 object 형식 상속
- 컴파일러는 자식을 부모로 간주할 수 있음.
- 박싱 / 언박싱으로 서로 다른 데이터 형식의 연산을 처리한다.
- 박싱과 언박싱
- 박싱 : 값형식 데이터를 object 형식에 담아 힙에 올리는 것
object a = 20;
- 언박싱 : 힙에 올라가 있는 데이터를 object에서 꺼내어 값 형식으로 옮기는 것.
- 박싱된 값을 꺼내 값 형식 변수에 저장하는 과정
- 박싱 : 값형식 데이터를 object 형식에 담아 힙에 올리는 것
- 형변환
- 정수형끼리의 형변환
- 작은 형식 → 큰 형식 : OK
- 큰 형식 → 작은 형식
- 작은 형식에 담을 수 있는 크기의 데이터 : OK
- 작은 형식에 담을 수 없는 크기의 데이터 : Overflow
- 부동 소수점 형식 사이 형변환
- Overflow는 없음, 대신 정밀성에 손상.
- 소수를 2진수로 메모리에 저장했다가 10진수로 변환한 뒤 다시 2진수로 변환하여 기록
- 2진수로 표현하는 소수가 온전하지 않다.
- 부호 있는 정수와 없는 정수 사이 형변환
int x = -30; uint y = (uint)x;
- 부동 소수점 형식과 정수 형식 사이 형변환
- 소수점 아래는 버림
- 반올림도 없음.
- 문자열과 숫자 사이의 형변환
- Parse()
- int a = int.Parse(num);
- ToString() : object에게서 물려받은 ToString() 메서드를 재정의 한 것
- string a = b.ToString();
- Parse()
- 정수형끼리의 형변환
- 상수와 열거 형식 : 변경 불가.
- 사용이유
- 변경 가능 데이터와 변경 불가 데이터의 명시적 구분
- (반복해서 작성하는 동일 문자열의 경우) 오타 방지
- 상수형

- 선언 후 데이터 변경 불가.
- 열거형
- 여러 개의 상수를 열거하는 형식

- 지정하지 않은 경우 첫 요소 : 0, 두번째 요소 : 1, …
- 열거 형식의 요소가 어떤 값을 갖느냐는 별 의미가 없기 때문.
- 사용이유
Uploaded by N2T
